

در اواخر دهه 1980، شبکههای عصبی به دلیل اختراع روشهای یادگیری کارآمد و ساختارهای شبکهای مختلف، به موضوعی رایج در حوزه یادگیری ماشین (ML) و همچنین هوش مصنوعی (AI) تبدیل شدند. شبکههای پرسپترون چندلایه آموزش دیده توسط الگوریتمهای نوع «انتشار به عقب»، نقشههای خود سازمان دهنده و شبکههای تابع پایه شعاعی چنین روشهای نوآورانهای بودند. در حالی که شبکههای عصبی با موفقیت در بسیاری از برنامهها استفاده میشوند، علاقه به تحقیق در مورد این موضوع بعداً کاهش یافت.
پس از آن، در سال 2006، «یادگیری عمیق» (DL) توسط Hinton و همکاران معرفی شد که بر اساس مفهوم شبکه عصبی مصنوعی (ANN) بود. یادگیری عمیق پس از آن به موضوعی برجسته تبدیل شد و منجر به تولد دوباره در تحقیقات شبکههای عصبی شد، از این رو، گاهی اوقات به عنوان «شبکههای عصبی نسل جدید» نامیده میشود. این به این دلیل است که شبکههای عمیق، زمانی که به درستی آموزش داده شوند، موفقیت قابل توجهی در انواع چالشهای طبقهبندی و رگرسیون به دست آوردهاند.
امروزه، فناوری DL به دلیل قابلیت یادگیری آن از دادههای داده شده، به عنوان یکی از موضوعات داغ در حوزه یادگیری ماشین، هوش مصنوعی و همچنین علم داده و تجزیه و تحلیل در نظر گرفته میشود. بسیاری از شرکتها از جمله گوگل، مایکروسافت، نوکیا و غیره آن را به طور فعال مطالعه میکنند زیرا میتواند نتایج قابل توجهی در مشکلات و مجموعه دادههای طبقهبندی و رگرسیون مختلف ارائه دهد.
از نظر حوزه کاری، DL به عنوان زیرمجموعهای از ML(یادگیری ماشین) و AI(هوش مصنوعی) در نظر گرفته میشود و بنابراین DL را میتوان به عنوان یک تابع هوش مصنوعی در نظر گرفت که تقلیدی از پردازش داده توسط مغز انسان است. محبوبیت جهانی «یادگیری عمیق» روز به روز در حال افزایش است، همانطور که در مقاله قبلی مابر اساس دادههای تاریخی جمعآوریشده از Google Trends نشان داده شده است. یادگیری عمیق از نظر کارایی با افزایش حجم داده با یادگیری ماشین استاندارد متفاوت است، که به طور خلاصه در بخش «چرایی یادگیری عمیق در تحقیقات و کاربردهای امروزی؟» مورد بحث قرار گرفته است.
فناوری DL از لایههای متعددی برای نشان دادن انتزاع دادهها برای ساخت مدلهای محاسباتی استفاده میکند. در حالی که یادگیری عمیق به دلیل تعداد زیاد پارامترها زمان زیادی را برای آموزش یک مدل صرف میکند، اما در مقایسه با سایر الگوریتمهای یادگیری ماشین، زمان کمی را برای اجرا در طول آزمایش صرف میکند .
در حالی که انقلاب صنعتی چهارم (4IR یا Industry 4.0) امروزه به طور معمول بر «اتوماسیون، سیستمهای هوشمند» مبتنی بر فناوری تمرکز دارد، فناوری DL که از ANN نشأت گرفته است، به یکی از فناوریهای مرکزی برای دستیابی به این هدف تبدیل شده است. یک شبکه عصبی معمولی عمدتاً از بسیاری عناصر پردازش یا پردازندههای ساده و متصل به نام نرون تشکیل شده است که هر کدام مجموعهای از فعالسازیهای با ارزش واقعی را برای نتیجه هدف تولید میکنند. شکل 1 یک نمایش شماتیک از مدل ریاضی یک نورون مصنوعی، یعنی عنصر پردازش را نشان میدهد، که ورودی (X)، وزن (w), سوگیری (b)، تابع جمع (Σ)، تابع فعالسازی (f) و سیگنال خروجی مربوطه (y) را برجسته میکند.
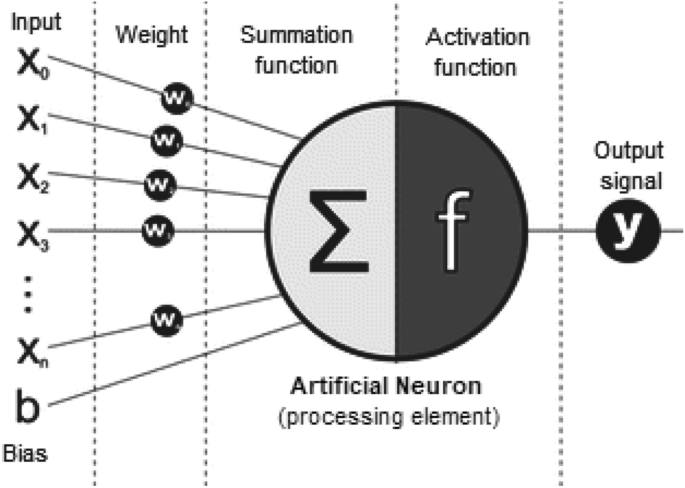
فناوری DL مبتنی بر شبکه عصبی اکنون در بسیاری از زمینهها و حوزههای تحقیقاتی مانند مراقبتهای بهداشتی، تجزیه و تحلیل احساسات، پردازش زبان طبیعی، تشخیص بصری، هوش تجاری، امنیت سایبری و موارد دیگر که در بخشهای بعدی این مقاله خلاصه شده است، به طور گسترده اعمال میشود.
با وجود موفقیت مدلهای یادگیری عمیق در حوزههای کاربردی مختلف که در بالا ذکر شد، ساخت یک مدل مناسب یادگیری عمیق به دلیل ماهیت پویا و تغییرات مسائل و دادههای دنیای واقعی، کار چالش برانگیزی است. علاوه بر این، مدلهای یادگیری عمیق به طور معمول به عنوان ماشینهای «جعبه سیاه» در نظر گرفته میشوند که توسعه استاندارد تحقیقات و کاربردهای یادگیری عمیق را مختل میکنند. بنابراین برای درک بهتر، در این مقاله دیدگاهی ساختاریافته و جامع در مورد تکنیکهای یادگیری عمیق را با توجه به تغییرات در مشکلات و وظایف دنیای واقعی ارائه میکنیم.
برای رسیدن به هدف خود، به طور خلاصه تکنیکهای مختلف یادگیری عمیق را مورد بحث قرار میدهیم و طبقهبندی را با در نظر گرفتن سه دسته اصلی ارائه میکنیم:
ما چنین دستههایی را بر اساس ماهیت و قابلیتهای یادگیری تکنیکهای مختلف دیپ لرنینگ و نحوه استفاده از آنها برای حل مشکلات در برنامههای دنیای واقعی در نظر میگیریم.
علاوه بر این، شناسایی مسائل کلیدی تحقیق و چشم اندازهای آینده از جمله بازنمایی مؤثر داده، طراحی الگوریتم جدید، یادگیری داده محور ابرپارامتر، و بهینهسازی مدل، ادغام دانش دامنه، تطبیق با دستگاههای با منابع محدود و غیره یکی از اهداف کلیدی این مطالعه است که میتواند منجر به «مدلسازی نسل آینده یادگیری عمیق» شود. بنابراین هدف این مقاله کمک به افراد در دانشگاه و صنعت به عنوان یک راهنمای مرجع است که میخواهند سیستمهای هوشمند و مبتکر مبتنی بر داده را بر اساس تکنیکهای یادگیری عمیق تحقیق و توسعه دهند.
موضوعات اصلی این مقاله به شرح زیر خلاصه می شود:
این مقاله بر جنبههای مختلف مدلسازی یادگیری عمیق تمرکز دارد، یعنی قابلیتهای یادگیری تکنیکهای یادگیری عمیق در ابعاد مختلف مانند وظایف تحت نظارت یا بدون نظارت، برای عملکرد به صورت خودکار و هوشمند، که میتواند به عنوان فناوری هستهای انقلاب صنعتی چهارم (Industry 4.0) امروز عمل کند.
ما طیف وسیعی از تکنیکهای برجسته یادگیری عمیق را بررسی میکنیم و طبقهبندی را با در نظر گرفتن تغییرات در وظایف یادگیری عمیق و نحوه استفاده از آنها برای اهداف مختلف ارائه میکنیم. در طبقهبندی خود، تکنیکها را به سه دسته اصلی مانند شبکههای عمیق برای یادگیری تحت نظارت یا تبعیضی، یادگیری بدون نظارت یا تولیدکننده، و همچنین شبکههای عمیق برای یادگیری ترکیبی و سایر موارد مرتبط تقسیم میکنیم.
ما چندین حوزه کاربردی بالقوه یادگیری عمیق در دنیای واقعی را خلاصه کردهایم تا به توسعهدهندگان و همچنین محققان در گسترش دیدگاههایشان در مورد تکنیکهای یادگیری عمیق کمک کنیم. دستههای مختلف تکنیکهای یادگیری عمیق که در طبقهبندی ما برجسته شدهاند را میتوان برای حل مسائل مختلف بر اساس آن به کار برد.
در نهایت، ما به ده جنبه بالقوه با جهتهای تحقیق برای مدلسازی یادگیری عمیق نسل آینده برای انجام تحقیقات و توسعه سیستمهای آتی اشاره و آنها را مورد بحث قرار میدهیم.
این مقاله به شرح زیر سازماندهی شده است:
بخش «چرا یادگیری عمیق در تحقیقات و کاربردهای امروزی؟» توضیح می دهد که چرا یادگیری عمیق برای ساخت سیستمهای هوشمند مبتنی بر داده مهم است. در بخش «تکنیکها و کاربردهای یادگیری عمیق»، طبقهبندی یادگیری عمیق خود را با در نظر گرفتن تغییرات وظایف یادگیری عمیق و نحوه استفاده از آنها در حل مسائل دنیای واقعی ارائه میکنیم و به طور خلاصه تکنیکها را با خلاصهسازی حوزههای کاربرد بالقوه مورد بحث قرار میدهیم. همچنین ما قسمت «مسیرهای تحقیق و جنبههای آینده»، را به مباحث مختلف تحقیقاتی مدلسازی مبتنی بر یادگیری عمیق اختصاص داده ایم و موضوعات امیدوارکننده برای تحقیقات آینده را در محدوده مطالعه خود برجسته میکنیم. در نهایت، بخش «سخن پایانی» این مقاله را جمعبندی میکند.
چرا یادگیری عمیق در تحقیقات و کاربردهای امروز اهمیت دارد؟
تمرکز اصلی انقلاب صنعتی چهارم (Industry 4.0) امروزه به طور معمول بر اتوماسیون مبتنی بر فناوری، سیستمهای هوشمند و باهوش در حوزههای کاربردی مختلف از جمله مراقبتهای بهداشتی هوشمند، هوش تجاری، شهرهای هوشمند، هوش امنیت سایبری و موارد دیگر است [95].
رویکردهای دیپ لرنینگ از نظر عملکرد در طیف وسیعی از برنامهها، بهویژه بهعنوان راهحلی عالی برای کشف معماری پیچیده در دادههای با ابعاد بالا، بهطور چشمگیری رشد کردهاند. بنابراین، تکنیکهای یادگیری عمیق به دلیل قابلیتهای یادگیری عالی خود از دادههای تاریخی، میتوانند نقش کلیدی در ساخت سیستمهای هوشمند مبتنی بر داده مطابق با نیازهای امروز ایفا کنند. در نتیجه، یادگیری عمیق میتواند از طریق قدرت اتوماسیون و یادگیری از تجربه، دنیا و همچنین زندگی روزمره انسانها را تغییر دهد.
بنابراین، فناوری یادگیری عمیق با هوش مصنوعی ، یادگیری ماشین و علم داده با تجزیه و تحلیل پیشرفته که حوزههای شناخته شدهای در علوم کامپیوتر، به ویژه محاسبات هوشمند امروزی هستند، مرتبط است. در بخش بعدی، ابتدا در مورد جایگاه یادگیری عمیق در هوش مصنوعی یا اینکه چگونه فناوری یادگیری عمیق با این حوزههای محاسبات مرتبط است، بحث میکنیم.
جایگاه یادگیری عمیق در هوش مصنوعی
امروزه، هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL) سه اصطلاح رایج هستند که گاهی اوقات به طور مترادف برای توصیف سیستمها یا نرمافزارهایی که هوشمندانه رفتار میکنند استفاده میشوند. در شکل 2، ما موقعیت یادگیری عمیق را در مقایسه با یادگیری ماشین و هوش مصنوعی نشان میدهیم. طبق شکل 2، یادگیری عمیق بخشی از یادگیری ماشین و همچنین بخشی از حوزه وسیع هوش مصنوعی است.
به طور کلی، هوش مصنوعی رفتار و هوش انسانی را در ماشینها یا سیستمها ادغام میکند، در حالی که یادگیری ماشین روشی برای یادگیری از داده یا تجربه است که ساخت مدل تحلیلی را به صورت خودکار انجام میدهد. یادگیری عمیق نیز نشاندهنده روشهای یادگیری از دادههایی است که محاسبات از طریق شبکههای عصبی چندلایه و پردازش انجام میشود. اصطلاح «عمیق» در روششناسی یادگیری عمیق به مفهوم سطوح یا مراحل متعدد پردازش داده برای ساخت یک مدل مبتنی بر داده اشاره دارد.
بنابراین، یادگیری عمیق را میتوان بهعنوان یکی از فناوریهای مرکزی هوش مصنوعی در نظر گرفت، مرزی برای هوش مصنوعی که میتواند برای ساخت سیستمهای هوشمند و اتوماسیون استفاده شود. از همه مهمتر، هوش مصنوعی را به سطح جدیدی به نام «هوش مصنوعی هوشمندتر» سوق میدهد. از آنجایی که یادگیری عمیق قادر به یادگیری از دادهها است، ارتباط قوی با «علم داده» نیز دارد. به طور معمول، علم داده کل فرآیند یافتن معنا یا بینش در دادهها را در یک حوزه خاص از مشکل نشان میدهد، جایی که روشهای یادگیری عمیق میتوانند برای تجزیه و تحلیل پیشرفته و تصمیمگیری هوشمندانه نقش کلیدی داشته باشند.
در مجموع، میتوانیم نتیجهگیری کنیم که فناوری یادگیری عمیق قادر است دنیای فعلی را به طور خاص از نظر یک موتور محاسباتی قدرتمند تغییر دهد و به اتوماسیون مبتنی بر فناوری، سیستمهای هوشمند و باهوش کمک کند و به همین ترتیب به هدف صنعت 4.0 برسد.

از آنجایی که مدلهای دیپ لرنینگ از دادهها یاد میگیرند، درک عمیق و نمایش دادهها برای ساخت یک سیستم هوشمند مبتنی بر داده در یک حوزه کاربردی خاص مهم است. در دنیای واقعی، دادهها میتوانند اشکال مختلفی داشته باشند که معمولاً برای مدلسازی یادگیری عمیق به صورت زیر نشان داده میشوند:
دادههای ترتیبی (توالی): دادههای ترتیبی هر نوع دادهای هستند که در آن ترتیب مهم است، به عنوان مثال مجموعهای از توالیها. هنگام ساخت مدل، باید به طور صریح ماهیت ترتیبی دادههای ورودی را در نظر گرفت. جریانهای متن، قطعات صدا، کلیپهای ویدیویی، دادههای سری زمانی، برخی از نمونههای دادههای ترتیبی هستند.
دادههای تصویری یا دو بعدی: یک تصویر دیجیتال از یک ماتریس تشکیل شده است که یک آرایه مستطیلی از اعداد، نمادها یا عبارات است که به صورت ردیفها و ستونها در یک آرایه دو بعدی از اعداد مرتب شدهاند. ماتریس، پیکسل، وکسل و عمق بیت چهار ویژگی ضروری یا پارامترهای اساسی یک تصویر دیجیتال هستند.
دادههای جدولی: یک مجموعه داده جدولی عمدتاً از ردیفها و ستونها تشکیل شدهاست. بنابراین، مجموعه دادههای جدولی حاوی دادهها به صورت ستونی مانند جدول پایگاه داده است. هر ستون (میدان) باید یک نام داشته باشد و هر ستون ممکن است فقط حاوی دادههایی از نوع تعریف شده باشد. به طور کلی، این یک چیدمان منطقی و سیستماتیک دادهها به صورت ردیفها و ستونهایی است که بر اساس ویژگیهای داده یا ویژگیها بنا شدهاست. مدلهای یادگیری عمیق میتوانند کارآمدانه از دادههای جدولی یاد بگیرند و به ما امکان میدهند سیستمهای هوشمند مبتنی بر داده بسازیم.
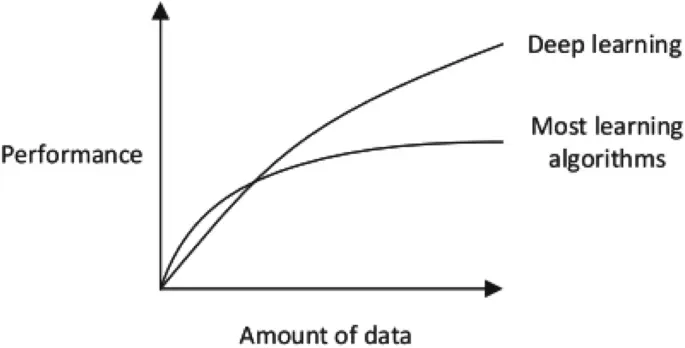
اشکال دادهای که در بالا مورد بحث قرار گرفت، در حوزههای کاربردی واقعی یادگیری عمیق رایج هستند. دستههای مختلف تکنیکهای یادگیری عمیق بسته به ماهیت و ویژگیهای داده عملکرد متفاوتی دارند که به طور خلاصه در بخش «تکنیکها و کاربردهای یادگیری عمیق» با ارائه طبقهبندی مورد بحث قرار خواهد گرفت. با این حال، در بسیاری از حوزههای کاربردی دنیای واقعی، تکنیکهای استاندارد یادگیری ماشین، به ویژه تکنیکهای مبتنی بر منطق یا درختی بسته به ماهیت برنامه کاربردی عملکرد قابل توجهی دارند. شکل 3 همچنین مقایسه عملکرد مدلسازی یادگیری عمیق و یادگیری ماشین را با در نظر گرفتن حجم داده نشان میدهد. در ادامه، بر اساس تمرکز اصلی ما در این مقاله، چندین مورد را که یادگیری عمیق برای حل مشکلات دنیای واقعی مفید است، برجسته میکنیم.
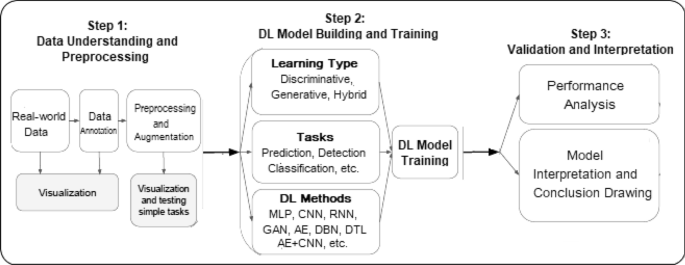
یک مدل یادگیری عمیق معمولاً مراحل پردازشی مشابه با مدلسازی یادگیری ماشین را دنبال میکند. در شکل 4، ما یک گردش کار یادگیری عمیق را برای حل مشکلات دنیای واقعی نشان دادهایم که از سه مرحله پردازش تشکیل شده است، مانند درک و پیش پردازش داده، ساخت و آموزش مدل یادگیری عمیق، اعتبارسنجی و تفسیر. با این حال، بر خلاف مدلسازی یادگیری ماشین ، استخراج ویژگی در مدل یادگیری عمیق به صورت خودکار و نه دستی انجام میشود.
برخی از نمونههای تکنیکهای یادگیری ماشین که به طور رایج در حوزههای کاربردی مختلف استفاده میشوند عبارتند از: همسایه نزدیکترین k، ماشینهای بردار پشتیبان، درخت تصمیم، جنگل تصادفی، بیز ساده، رگرسیون خطی، قوانین انجمن، خوشهبندی k-means . از سوی دیگر، مدل یادگیری عمیق شامل شبکه عصبی کانولوشنال، شبکه عصبی بازگشتی، اتوکدر، شبکه باور عمیق و موارد دیگر میشود که به طور خلاصه با حوزههای کاربردی بالقوه آنها در بخش 3 مورد بحث قرار گرفته است. در ادامه، ویژگیها و وابستگیهای کلیدی تکنیکهای یادگیری عمیق را که قبل از شروع به کار بر روی مدلسازی یادگیری عمیق برای کاربردهای دنیای واقعی باید در نظر گرفته شوند، مورد بحث قرار میدهیم.
یادگیری عمیق به طور معمول برای ساخت یک مدل مبتنی بر داده برای حوزه مسئله خاصی به حجم زیادی از داده وابسته است. دلیل این است که هنگامی که حجم داده کم باشد، الگوریتمهای یادگیری عمیق اغلب عملکرد ضعیفی دارند. با این حال، در چنین شرایطی، اگر از قوانین مشخصشده استفاده شود، عملکرد الگوریتمهای استاندارد یادگیری ماشین بهبود مییابد.
الگوریتمهای یادگیری عمیق در حین آموزش یک مدل با مجموعه دادههای بزرگ به محاسبات پیچیده زیادی نیاز دارند. هرچه محاسبات بیشتر باشد، مزیت GPU نسبت به CPU بیشتر میشود، GPU عمدتا برای بهینهسازی کارآمد عملیات استفاده میشود. بنابراین، برای کارکرد صحیح با آموزش یادگیری عمیق، سختافزار GPU ضروری است. بنابراین، یادگیری عمیق نسبت به روشهای استاندارد یادگیری ماشین، بیشتر به ماشینهای با کارایی بالا با GPU وابسته است.
مهندسی ویژگی فرآیند استخراج ویژگیها (ویژگیها، خواص و خصوصیات) از دادههای خام با استفاده از دانش دامنه است. تمایز اساسی بین یادگیری عمیق و سایر تکنیکهای یادگیری ماشین، تلاش برای استخراج مستقیم ویژگیهای سطح بالا از دادهها است. بنابراین، یادگیری عمیق زمان و تلاش لازم برای ساخت یک استخراجکننده ویژگی برای هر مسئله را کاهش میدهد.
به طور کلی، آموزش یک الگوریتم یادگیری عمیق به دلیل تعداد زیاد پارامتر در الگوریتم یادگیری عمیق زمان زیادی میبرد؛ بنابراین، فرآیند آموزش مدل زمان بیشتری میبرد. به عنوان مثال، مدلهای یادگیری عمیق میتوانند بیش از یک هفته طول بکشد تا یک جلسه آموزشی را تکمیل کنند، در حالی که آموزش با الگوریتمهای یادگیری ماشین زمان نسبتاً کمی نیاز دارد، تنها چند ثانیه تا چند ساعت. در هنگام آزمایش، الگوریتمهای یادگیری عمیق در مقایسه با برخی از روشهای یادگیری ماشین، زمان بسیار کمی برای اجرا نیاز دارند.
قابلیت تفسیر هنگام مقایسه یادگیری عمیق با یادگیری ماشین یک عامل مهم است. توضیح چگونگی به دست آمدن نتیجه یادگیری عمیق دشوار است، یعنی یک «جعبه سیاه». از سوی دیگر، الگوریتمهای یادگیری ماشین، به ویژه تکنیکهای یادگیری ماشین مبتنی بر قانون، قوانین منطقی صریح (اگر-آنگاه) را برای تصمیمگیری ارائه میدهند که به راحتی برای انسان قابل تفسیر است. برای مثال، در کارهای قبلی خود، چندین تکنیک مبتنی بر قوانین یادگیری ماشین را ارائه کردهایم که در آن قوانین استخراجشده برای انسان قابل درک و تفسیر، بهروزرسانی یا حذف آنها بر اساس برنامههای کاربردی هدف آسانتر است.
مهمترین تمایز بین یادگیری عمیق و یادگیری ماشین معمولی، عملکرد آن با رشد تصاعدی دادهها است.
در این بخش، ما به بررسی انواع مختلف تکنیکهای شبکه عصبی عمیق میپردازیم که به طور معمول چندین لایه از مراحل پردازش اطلاعات را در ساختارهای سلسله مراتبی برای یادگیری در نظر میگیرند. یک شبکه عصبی عمیق معمولی حاوی چندین لایه پنهان از جمله لایههای ورودی و خروجی است. شکل 5 ساختار کلی یک شبکه عصبی عمیق (ℎ(x) = W2σ(W1x + b1) + b2 و N ≥ 2) را در مقایسه با یک شبکه کمعمق (ℎ(x) = W1x + b) نشان میدهد. همچنین در این بخش طبقهبندی خود را بر روی تکنیکهای یادگیری عمیق بر اساس نحوه استفاده از آنها برای حل مشکلات مختلف ارائه میکنیم.
با این حال، قبل از کاوش در جزئیات تکنیکهای دیپ لرنینگ، بررسی انواع مختلف وظایف یادگیری مانند (الف) تحت نظارت: رویکردی مبتنی بر وظیفه که از دادههای آموزشی برچسبگذاریشده استفاده میکند، (ب) بدون نظارت: فرآیندی مبتنی بر داده که مجموعه دادههای بدون برچسب را تجزیه و تحلیل میکند، (پ) نیمه-نظارت: ترکیبی از هر دو روش تحت نظارت و بدون نظارت، و (ت) تقویتی: رویکردی مبتنی بر محیط، که به طور خلاصه در مقاله قبلی ما مورد بحث قرار گرفته است، مفید است.
بنابراین، برای ارائه طبقهبندی خود، تکنیکهای یادگیری عمیق را به طور گسترده به سه دسته اصلی تقسیم میکنیم: (الف) شبکههای عمیق برای یادگیری تحت نظارت یا تبعیضی، (ب) شبکههای عمیق برای یادگیری بدون نظارت یا تولیدکننده، و (پ) شبکههای عمیق برای یادگیری ترکیبی که هر دو مورد را با هم ترکیب میکند، همانطور که در شکل 6 نشان داده شدهاست. در ادامه، به طور خلاصه هر یک از این تکنیکها را که میتوانند برای حل مشکلات دنیای واقعی در حوزههای کاربردی مختلف بر اساس قابلیتهای یادگیری آنها استفاده شوند، مورد بحث قرار میدهیم.

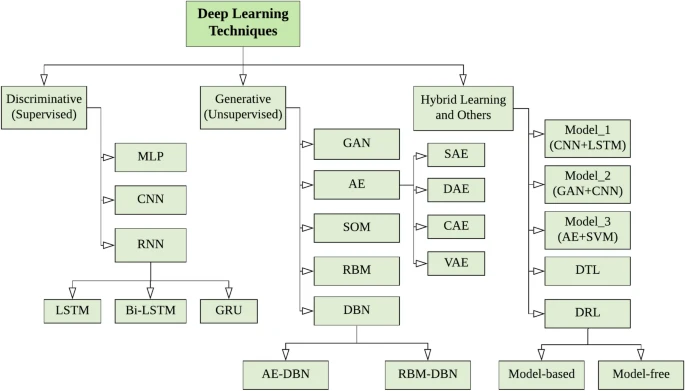
این دسته از تکنیکهای یادگیری عمیق برای ارائه یک تابع تبعیضی در برنامههای تحت نظارت یا طبقهبندی استفاده میشود. معماریهای عمیق تبعیضی به طور معمول برای طبقهبندی الگو با توصیف توزیعهای پسین کلاسهای مشروط بر دادههای قابل مشاهده، قدرت تبعیضی ارائه میدهند. معماریهای تبعیضی به طور عمده شامل پرسپترون چند لایه (MLP)، شبکههای عصبی کانولوشنال (CNN یا ConvNet)، شبکههای عصبی بازگشتی (RNN) به همراه انواع آنها هستند. در ادامه به طور خلاصه به بحث در مورد این تکنیکها میپردازیم.
پرسپترون چند لایه (MLP) ، یک رویکرد یادگیری تحت نظارت، نوعی شبکه عصبی مصنوعی پیشخور (ANN) است. همچنین به عنوان معماری بنیادی شبکههای عصبی عمیق (DNN) یا یادگیری عمیق شناخته میشود. یک MLP معمولی یک شبکه کاملاً متصل است که از یک لایه ورودی که دادههای ورودی را دریافت میکند، یک لایه خروجی که تصمیمی میگیرد یا پیشبینیای درباره سیگنال ورودی انجام میدهد، و یک یا چند لایه پنهان بین این دو تشکیل شدهاست که به عنوان موتور محاسباتی شبکه در نظر گرفته میشوند. خروجی یک شبکه MLP با استفاده از انواع مختلفی از توابع فعالسازی، که همچنین به عنوان توابع انتقال شناخته میشوند، مانند ReLU (واحد خطی اصلاحشده)، Tanh، Sigmoid و Softmax تعیین میشود.
برای آموزش MLP از الگوریتم “انتشار پسرو” که به طور گسترده استفاده میشود، یک تکنیک یادگیری تحت نظارت که به عنوان اساسیترین بلوک سازنده یک شبکه عصبی نیز شناخته میشود، استفاده میکند. در طول فرآیند آموزش، رویکردهای مختلف بهینهسازی مانند نزول شیب تصادفی (SGD)، BFGS حافظه محدود (L-BFGS) و تخمین لحظه تطبیقی (Adam) اعمال میشوند. MLP نیاز به تنظیم چندین ابرپارامتر مانند تعداد لایههای پنهان، نرونها و تکرارها دارد که میتواند حل یک مدل پیچیده را از نظر محاسباتی پرهزینه کند. با این حال، MLP از طریق برازش جزئی، این مزیت را ارائه میدهد که مدلهای غیرخطی را به صورت آنلاین یا لحظهای یاد بگیرد.
شبکه عصبی کانولوشنال (CNN یا ConvNet) یک معماری محبوب یادگیری عمیق تبعیضی است که مستقیماً از ورودی یاد میگیرد بدون نیاز به استخراج ویژگی توسط انسان. شکل 7 نمونهای از یک CNN شامل چندین لایه کانولوشن و استخرگیری را نشان میدهد. در نتیجه، CNN طراحی شبکههای عصبی مصنوعی سنتی مانند شبکههای MLP با قاعده را بهبود میبخشد. هر لایه در CNN پارامترهای بهینه را برای خروجی معنیدار در نظر میگیرد و همچنین پیچیدگی مدل را کاهش میدهد. CNN همچنین از «ریزش» استفاده میکند که میتواند با مشکل بیشبرازش (over-fitting) که ممکن است در یک شبکه سنتی رخ دهد، مقابله کند.
شبکههای عصبی کانولوشنال (CNN) به طور خاص برای برخورد با انواع اشکال دو بعدی در نظر گرفته شدهاند و از این رو به طور گسترده در تشخیص بصری، تحلیل تصویر پزشکی، بخشبندی تصویر، پردازش زبان طبیعی و موارد دیگر به کار میروند. توانایی کشف خودکار ویژگیهای ضروری از ورودی بدون نیاز به دخالت انسان، آن را نسبت به یک شبکه سنتی قدرتمندتر میکند. انواع مختلفی از CNN در این زمینه وجود دارد که شامل گروه هندسه بصری (VGG)، AlexNet ، Xception ، Inception ، ResNet و غیره میشود که میتوان از آنها در حوزههای کاربردی مختلف بسته به قابلیتهای یادگیری آنها استفاده کرد.

شبکه عصبی بازگشتی (RNN) یک شبکه عصبی محبوب دیگر است که از دادههای ترتیبی یا سری زمانی استفاده میکند و خروجی حاصل از مرحله قبل را به عنوان ورودی مرحله جاری تغذیه میکند. شبکههای بازگشتی مانند شبکههای پیشخور و CNN از ورودی آموزشی یاد میگیرند، با این حال، با «حافظه» خود متمایز میشوند که به آنها اجازه میدهد از طریق استفاده از اطلاعات ورودیهای قبلی بر ورودی و خروجی فعلی تأثیر بگذارند.
برخلاف DNN معمولی که فرض میکند ورودیها و خروجیها مستقل از یکدیگر هستند، خروجی RNN به عناصر قبلی درون توالی وابسته است. با این حال، شبکههای بازگشتی استاندارد مشکل گرادیانهای در حال ناپدید شدن (vanishing gradients) را دارند که یادگیری توالیهای دادهای طولانی را چالش برانگیز میکند. در ادامه به بررسی چندین نوع محبوب از شبکههای بازگشتی میپردازیم که این مسائل را به حداقل میرساند و در بسیاری از حوزههای کاربردی دنیای واقعی عملکرد خوبی دارند.
این یک شکل محبوب از معماری RNN است که برای مقابله با مشکل گرادیان در حال ناپدید شدن از واحدهای ویژهای استفاده میکند که توسط Hochreiter و همکارانش معرفی شد. یک سلول حافظه در یک واحد LSTM میتواند دادهها را برای مدت طولانی ذخیره کند و جریان اطلاعات به داخل و خارج از سلول توسط سه دروازه مدیریت میشود. برای مثال، «دروازه فراموشی» تعیین میکند که چه اطلاعاتی از سلول حالت قبلی به خاطر سپرده شود و چه اطلاعاتی که دیگر مفید نیست حذف شود، در حالی که «دروازه ورودی» تعیین میکند که کدام اطلاعات باید وارد سلول حالت شوند و «دروازه خروجی» خروجیها را تعیین و کنترل میکند.
شبکه LSTM از آنجایی که مسائل مربوط به آموزش یک شبکه بازگشتی را حل میکند، یکی از موفقترین RNNها در نظر گرفته میشود.
RNNهای دوطرفه دو لایه پنهان را که در جهتهای مخالف اجرا میشوند به یک خروجی واحد متصل میکنند و به آنها اجازه میدهند دادهها را از هر دو جهت گذشته و آینده دریافت کنند. RNNهای دوطرفه، برخلاف شبکههای بازگشتی سنتی، برای پیشبینی همزمان جهتهای زمانی مثبت و منفی آموزش داده میشوند. یک LSTM دوطرفه که اغلب به عنوان BiLSTM شناخته میشود، توسعهای از LSTM استاندارد است که میتواند عملکرد مدل را در مسائل طبقهبندی توالی (sequence classification) افزایش دهد [113]. این یک مدل پردازش توالی است که شامل دو LSTM است: یکی ورودی را به جلو و دیگری آن را به عقب میبرد. LSTM دوطرفه به طور خاص یک انتخاب محبوب در وظایف پردازش زبان طبیعی است.
واحد بازگشتی گیتدار (GRU) نوع دیگری از شبکه بازگشتی محبوب است که از روشهای گیتدهی برای کنترل و مدیریت جریان اطلاعات بین سلولها در شبکه عصبی استفاده میکند، که توسط Cho و همکارانش معرفی شد. GRU شبیه LSTM است، با این حال، پارامترهای کمتری دارد، زیرا یک دروازه بازنشانی و یک دروازه بهروزرسانی دارد اما فاقد دروازه خروجی است، همانطور که در شکل 8 نشان داده شدهاست. بنابراین، تفاوت کلیدی بین GRU و LSTM این است که GRU دارای دو دروازه (بازنشانی و بهروزرسانی) است در حالی که LSTM دارای سه دروازه (یعنی ورودی، خروجی و فراموشی) است.
به طور کلی، ویژگی اساسی یک شبکه بازگشتی این است که حداقل یک اتصال بازخورد دارد که به فعالسازیها اجازه حلقه زدن میدهد. این امکان را برای شبکهها فراهم میکند تا پردازش زمانی و یادگیری توالی را انجام دهند، مانند تشخیص یا بازتولید توالی، انجمن یا پیشبینی زمانی و غیره. در ادامه برخی از حوزههای کاربردی محبوب شبکههای بازگشتی مانند مسائل پیشبینی، ترجمه ماشینی، پردازش زبان طبیعی، خلاصهسازی متن، تشخیص گفتار و موارد دیگر آورده شدهاست.
این دسته از تکنیکهای دیپ لرنینگ به طور معمول برای مشخص کردن ویژگیهای همبستگی مرتبه بالا یا ویژگیها برای تجزیه و تحلیل یا سنتز الگو، و همچنین توزیعهای آماری مشترک دادههای قابل مشاهده و طبقات مرتبط با آنها استفاده میشود. ایده کلیدی معماریهای عمیق تولیدکننده این است که در طول فرآیند یادگیری، اطلاعات نظارتی دقیق مانند برچسبهای کلاس هدف مورد نظر نیستند.
در نتیجه، روشهای تحت این دسته اساساً برای یادگیری بدون نظارت اعمال میشوند زیرا روشها به طور معمول برای یادگیری ویژگی یا تولید و نمایش داده استفاده میشوند. بنابراین مدلسازی تولیدکننده میتواند به عنوان پیش پردازش برای وظایف یادگیری تحت نظارت نیز استفاده شود که دقت مدل تبعیضی را تضمین میکند. تکنیکهای رایج شبکه عصبی عمیق برای یادگیری بدون نظارت یا تولیدکننده عبارتند از شبکه مولد با تنازع (GAN)، خودرمزگذار (AE)، ماشین بولتزمن محدود (RBM)، نقشه خود سازمانده (SOM) و شبکه باور عمیق (DBN) به همراه انواع آنها.
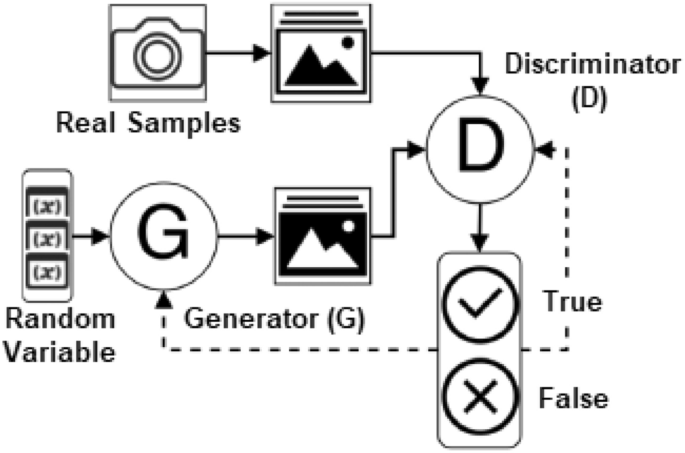
شبکه مولد با تنازع (GAN) که توسط ایان گودفلو طراحی شده است، نوعی معماری شبکه عصبی برای مدلسازی تولیدکننده است که برای ایجاد نمونههای جدید و موجه بر اساس تقاضا است. این شامل کشف و یادگیری خودکار قواعد یا الگوها در دادههای ورودی است تا بتوان از مدل برای تولید یا خروجی نمونههای جدید از مجموعه دادههای اصلی استفاده کرد.
همانطور که در شکل 9 نشان داده شدهاست، GANها از دو شبکه عصبی تشکیل شدهاند، یک ژنراتور (G) که دادههای جدیدی را با ویژگیهایی مشابه دادههای اصلی ایجاد میکند، و یک تمایزگر (D) که احتمال کشیده شدن نمونه بعدی از دادههای واقعی به جای دادههای ارائه شده توسط ژنراتور را پیشبینی میکند. بنابراین در مدلسازی GAN، هم ژنراتور و هم تمایزگر برای رقابت با یکدیگر آموزش داده میشوند. در حالی که ژنراتور سعی میکند با ایجاد دادههای واقعیتر، تمایزگر را فریب دهد و گیج کند، تمایزگر سعی میکند دادههای واقعی را از دادههای جعلی تولید شده توسط G تشخیص دهد.
به طور کلی، استقرار شبکه GAN برای وظایف یادگیری بدون نظارت طراحی شدهاست، اما بسته به وظیفه، ثابت شدهاست که راهحل بهتری برای یادگیری نیمه-نظارت و تقویتی نیز میباشد. همچنین از GANها در تحقیقات پیشرفته یادگیری انتقال برای اعمال همراستا کردن فضای ویژگی نهفته (latent feature space) استفاده میشود. مدلهای معکوس، مانند GAN دوطرفه (BiGAN) نیز میتوانند نقشهبرداری از دادهها به فضای نهفته را یاد بگیرند، مشابه روشی که مدل GAN استاندارد نقشهبرداری از فضای نهفته به توزیع داده را یاد میگیرد.
حوزههای کاربردی بالقوه شبکههای GAN شامل مراقبتهای بهداشتی، تحلیل تصویر، افزایش داده (data augmentation)، تولید ویدیو، تولید صدا، همهگیریها، کنترل ترافیک، امنیت سایبری و موارد دیگر است که به سرعت در حال افزایش است. به طور کلی، GANها خود را به عنوان یک حوزه جامع از توسعه مستقل داده و راهحلی برای مشکلاتی که نیاز به راهحل تولیدکننده دارند، تثبیت کردهاند.
خودرمزگذار (AE) یک تکنیک رایج یادگیری بدون نظارت است که در آن از شبکههای عصبی برای یادگیری بازنمایی استفاده میشود. به طور معمول، خودرمزگذارها برای کار با دادههای با ابعاد بالا استفاده میشوند و کاهش ابعاد توضیح میدهد که چگونه مجموعهای از دادهها نمایش داده میشود. خودرمزگذار از سه بخش رمزگر (encoder)، کد (code) و رمزگشا (decoder) تشکیل شدهاست. رمزگر ورودی را فشرده میکند و کدی را تولید میکند که رمزگشا بعداً از آن برای بازسازی ورودی استفاده میکند. اخیراً از خودرمزگذارها برای یادگیری مدلهای داده تولیدکننده استفاده شدهاست.
خودرمزگذار به طور گسترده در بسیاری از وظایف یادگیری بدون نظارت مانند کاهش ابعاد، استخراج ویژگی، کدگذاری کارآمد، مدلسازی تولیدکننده، حذف نویز، تشخیص ناهنجاری یا پرت (outlier) و غیره استفاده میشود. تحلیل مؤلفههای اصلی (PCA) که برای کاهش ابعاد مجموعه دادههای بزرگ نیز استفاده میشود، اساساً شبیه به یک AE تک لایه با یک تابع فعالسازی خطی است. خودرمزگذارهای با قاعده (regularized autoencoders) مانند خودرمزگذارهای کمتراکم (sparse)، حذف نویز (denoising) و انقباضی (contractive) برای یادگیری بازنمایی برای وظایف طبقهبندی بعدی مفید هستند، در حالی که از خودرمزگذارهای واریاسیونال که در ادامه مورد بحث قرار میگیرند، میتوان به عنوان مدلهای تولیدکننده استفاده کرد.
خودرمزگذار کمتراکمبه عنوان بخشی از الزامات آموزشی خود، دارای جریمهی کمتراکم (sparsity penalty) روی لایه کدگذاری است. SAEها ممکن است واحدهای پنهان بیشتری نسبت به ورودیها داشته باشند، اما تنها تعداد کمی از واحدهای پنهان مجاز به فعال شدن همزمان هستند، که منجر به یک مدل کمتراکم میشود. شکل 10 ساختار شماتیکی از یک خودرمزگذار کمتراکم با چندین واحد فعال در لایه پنهان را نشان میدهد. بنابراین، این مدل موظف است با توجه به محدودیتهای خود، به ویژگیهای آماری منحصر به فرد دادههای آموزشی پاسخ دهد.
خودرمزگذار حذف نویز، یک نوع از خودرمزگذار پایه است که با تغییر معیار بازسازی، سعی در بهبود بازنمایی (برای استخراج ویژگیهای مفید) دارد و بدین ترتیب خطر یادگیری تابع همانی (identity function) را کاهش میدهد. به عبارت دیگر، این مدل یک نقطه داده مخدوش را به عنوان ورودی دریافت میکند و برای بازیابی ورودی اصلی و بدون اعوجاج به عنوان خروجی خود از طریق به حداقل رساندن میانگین خطای بازسازی روی دادههای آموزشی، یعنی پاکسازی ورودی مخدوش یا حذف نویز، آموزش میبیند. بنابراین، در زمینه محاسبات، DAEها را میتوان به عنوان فیلترهای بسیار قدرتمندی در نظر گرفت که میتوان از آنها برای پیش پردازش خودکار استفاده کرد. برای مثال، یک خودرمزگذار حذف نویز میتواند برای پیش پردازش خودکار یک تصویر استفاده شود و در نتیجه کیفیت آن را برای دقت تشخیص افزایش دهد.
ایده پشت خودرمزگذار انقباضی، که توسط Rifai و همکارانش پیشنهاد شدهاست، این است که خودرمزگذارها را در برابر تغییرات کوچک در مجموعه داده آموزشی مقاوم کند. یک CAE در تابع هدف خود شامل یک قاعده صریح (explicit regularizer) است که مدل را مجبور میکند تا کدگذاری را یاد بگیرد که در برابر تغییرات کوچک در مقادیر ورودی مقاوم باشد. در نتیجه، حساسیت بازنمایی آموخته شده به ورودی آموزشی کاهش مییابد. در حالی که DAEها همانطور که در بالا ذکر شد، استحکام بازسازی را تشویق میکنند، CAEها استحکام بازنمایی را تشویق میکنند.
خودرمزگذار واریاسیونال (VAE) یک ویژگی کاملاً منحصر به فرد دارد که آن را از خودرمزگذار کلاسیک که در بالا مورد بحث قرار گرفت متمایز میکند و باعث میشود این روش برای مدلسازی تولیدکننده بسیار مؤثر باشد. VAEها، برخلاف خودرمزگذارهای سنتی که ورودی را به یک بردار نهفته (latent vector) نگاشت میکنند، دادههای ورودی را به پارامترهای یک توزیع احتمالی، مانند میانگین و واریانس توزیع گاوسی، نگاشت میکنند. یک VAE فرض میکند که دادههای منبع یک توزیع احتمالی زمینهای دارند و سپس سعی میکند پارامترهای توزیع را کشف کند. اگرچه این رویکرد در ابتدا برای یادگیری بدون نظارت طراحی شده بود، استفاده از آن در سایر حوزهها مانند یادگیری نیمه-نظارت و یادگیری تحت نظارت نیز نشان داده شدهاست.
اگرچه مفهوم اولیه خودرمزگذار (AE) معمولاً برای کاهش ابعاد یا یادگیری ویژگی بود که در بالا ذکر شد، به تازگی، خودرمزگذارها به عنوان یکی از روشهای محبوب در حوزه مدلسازی تولیدکننده، به خط مقدم آمدهاند. حتی شبکه مولد با تنازع نیز یکی از روشهای محبوب در این زمینه است. خودرمزگذارها به طور مؤثر در حوزههای مختلفی از جمله مراقبتهای بهداشتی، بینایی رایانه، تشخیص گفتار، امنیت سایبری، پردازش زبان طبیعی و موارد دیگر به کار گرفته شدهاند. به طور کلی، میتوانیم نتیجهگیری کنیم که خودرمزگذار و انواع آن میتوانند به عنوان یادگیری ویژگی بدون نظارت با معماری شبکه عصبی نقش مهمی ایفا کنند.
نقشه خودسامانده (SOM) یا نقشه کوهنن نوع دیگری از تکنیک یادگیری بدون نظارت برای ایجاد یک بازنمایی کمبعد (معمولاً دو بعدی) از یک مجموعه داده با ابعاد بالاتر است، در حالی که ساختار توپولوژیکی دادهها را حفظ میکند. SOM همچنین به عنوان یک الگوریتم کاهش ابعاد مبتنی بر شبکه عصبی شناخته میشود که به طور رایج برای خوشهبندی استفاده میشود. یک SOM با بارها جابجا کردن نورونهای خود به نزدیکترین نقاط داده با فرم توپولوژیکی مجموعه داده سازگار میشود و به ما امکان میدهد مجموعه دادههای عظیم را تجسم کنیم و خوشههای احتمالی را پیدا کنیم.
اولین لایه یک SOM لایه ورودی و لایه دوم لایه خروجی یا نقشه ویژگی است. برخلاف سایر شبکههای عصبی که از یادگیری تصحیح خطا مانند backpropagation با نزول شیب استفاده میکنند ، SOMها از یادگیری رقابتی استفاده میکنند که از یک تابع همسایگی برای حفظ ویژگیهای توپولوژیکی فضای ورودی استفاده میکند. SOM به طور گسترده در انواع کاربردها از جمله شناسایی الگو، تشخیص سلامت یا پزشکی، تشخیص ناهنجاری و تشخیص حمله ویروس یا کرم مورد استفاده قرار میگیرد.
مزیت اصلی استفاده از SOM این است که میتواند تجسم و تحلیل دادههای با ابعاد بالا را برای درک الگوها آسانتر کند. کاهش ابعاد و خوشهبندی شبکهای، مشاهده شباهتها در دادهها را آسان میکند. در نتیجه، SOMها بسته به ویژگیهای داده، میتوانند نقش مهمی در توسعه یک مدل مؤثر مبتنی بر داده برای حوزه مسئله خاص ایفا کنند.
ماشین بولتزمن محدود (RBM)نیز یک شبکه عصبی تصادفی تولیدکننده است که قادر به یادگیری توزیع احتمالی در ورودیهای خود میباشد. ماشینهای بولتزمن معمولاً از گرههای آشکار و پنهان تشکیل شدهاند و هر گره به تمام گرههای دیگر متصل است، که به ما کمک میکند با یادگیری نحوه عملکرد سیستم در شرایط عادی، بی نظمیها را درک کنیم. RBMها زیرمجموعهای از ماشینهای بولتزمن هستند که تعداد اتصالات بین لایههای آشکار و پنهان در آنها محدود است. این محدودیت باعث میشود الگوریتمهای آموزشی مانند الگوریتم واگرایی کنتراستی مبتنی بر گرادیان نسبت به الگوریتمهای مربوط به ماشینهای بولتزمن به طور کلی کارآمدتر باشند.
RBMها کاربردهایی در کاهش ابعاد، طبقهبندی، رگرسیون، فیلترین مشارکتی، یادگیری ویژگی، مدلسازی موضوع و بسیاری موارد دیگر پیدا کردهاند. در حوزه مدلسازی یادگیری عمیق، بسته به وظیفه، میتوان آنها را به صورت تحت نظارت یا بدون نظارت آموزش داد. به طور کلی، RBMها میتوانند به طور خودکار الگوها را در دادهها تشخیص دهند و مدلهای احتمالی یا تصادفی را توسعه دهند که برای انتخاب یا استخراج ویژگی و همچنین تشکیل یک شبکه باور عمیق (DBN) مورد استفاده قرار میگیر گیرند.
یک ماشین بولتزمن محدود (RBM)همچنین یک شبکه عصبی تصادفی تولیدکننده است که قادر به یادگیری توزیع احتمالی در ورودیهای خود میباشد. ماشینهای بولتزمن معمولاً از گرههای آشکار و پنهان تشکیل شدهاند و هر گره به تمام گرههای دیگر متصل است، که به ما کمک میکند با یادگیری نحوه عملکرد سیستم در شرایط عادی، بی نظمیها را درک کنیم. RBMها زیرمجموعهای از ماشینهای بولتزمن هستند که تعداد اتصالات بین لایههای آشکار و پنهان در آنها محدود است . این محدودیت باعث میشود الگوریتمهای آموزشی مانند الگوریتم واگرایی کنتراستی مبتنی بر گرادیان نسبت به الگوریتمهای مربوط به ماشینهای بولتزمن به طور کلی کارآمدتر باشند.
RBMها کاربردهایی در کاهش ابعاد، طبقهبندی، رگرسیون، فیلترین مشارکتی، یادگیری ویژگی، مدلسازی موضوع و بسیاری موارد دیگر پیدا کردهاند. در حوزه مدلسازی یادگیری عمیق، بسته به وظیفه، میتوان آنها را به صورت تحت نظارت یا بدون نظارت آموزش داد. به طور کلی، RBMها میتوانند به طور خودکار الگوها را در دادهها تشخیص دهند و مدلهای احتمالی یا تصادفی را توسعه دهند که برای انتخاب یا استخراج ویژگی و همچنین تشکیل یک شبکه باور عمیق (DBN) مورد استفاده قرار میگیرند.
شبکه باور عمیق (DBN) یک مدل گرافیکی تولیدکننده چند لایه است که با روی هم چیدن چندین شبکه بدون نظارت منفرد مانند اتوکدرها (AE) یا ماشینهای بولتزمن محدود (RBM) ساخته میشود، به گونهای که از لایه پنهان هر شبکه بهعنوان ورودی برای لایه بعدی استفاده میکند (یعنی به صورت متوالی وصل میشوند). بنابراین، میتوان یک DBN را به دو دسته تقسیم کرد: (۱) AE-DBN که به عنوان اتوکدر چیده شده شناخته میشود، و (۲) RBM-DBN که به عنوان ماشین بولتزمن محدود چیده شده شناخته میشود، که در آن AE-DBN از اتوکدرها و RBM-DBN از ماشینهای بولتزمن محدود تشکیل شده است، که قبلا مورد بحث قرار گرفت. هدف نهایی توسعه یک تکنیک آموزش بدون نظارت سریعتر برای هر زیرشبکه است که به واگرایی متضاد وابسته است. DBN میتواند بر اساس ساختار عمیق خود، بازنمایی سلسله مراتبی از دادههای ورودی را ثبت کند.
ایده اصلی پشت DBN، آموزش شبکههای عصبی پیشرو بدون نظارت با دادههای برچسبگذاری نشده قبل از تنظیم دقیق شبکه با ورودی برچسبگذاری شده است. یکی از مهمترین مزایای DBN، در مقایسه با شبکههای یادگیری کمعمق معمولی، این است که امکان کشف الگوهای عمیق را فراهم میکند که به توانایی استدلال و درک تفاوتهای عمیق بین دادههای نرمال و دادههای حاوی خطا منجر میشود. یک DBN پیوسته، صرفاً توسعهای از یک DBN استاندارد است که به جای دادههای دودویی، دامنه پیوستهای از اعداد اعشاری را مجاز میداند. به طور کلی، مدل DBN به دلیل قابلیتهای قوی در استخراج ویژگی و طبقهبندی میتواند نقش کلیدی در طیف وسیعی از کاربردهای دادههای با ابعاد بالا ایفا کند و به یکی از موضوعات مهم در زمینه شبکههای عصبی تبدیل شود.
به طور خلاصه، تکنیکهای یادگیری تولیدکننده که در بالا مورد بحث قرار گرفت، به طور معمول به ما امکان میدهند تا از طریق تحلیل اکتشافی، بازنمایی جدیدی از دادهها ایجاد کنیم. در نتیجه، از این شبکههای تولیدکننده عمیق میتوان به عنوان پیشپردازش برای وظایف یادگیری تحت نظارت یا تبعیضی استفاده کرد، و همچنین دقت مدل را تضمین کرد، جایی که یادگیری بدون نظارت بازنمایی میتواند به بهبود تعمیم طبقهبند منجر شود.
علاوه بر دستههای یادگیری عمیق که در بالا مورد بحث قرار گرفت، شبکههای عمیق ترکیبی و چندین رویکرد دیگر مانند یادگیری عمیق انتقالی (DTL) و یادگیری تقویتی عمیق (DRL) رویکردهای محبوب هستند که در ادامه به آنها پرداخته میشود.
مدلهای تولیدکننده با قابلیت تطبیقپذیری بالا قادر به یادگیری از دادههای برچسبدار و بدون برچسب هستند. از سوی دیگر، مدلهای تبعیضی نمیتوانند از دادههای بدون برچسب یاد بگیرند، اما در وظایف تحت نظارت از همتایان تولیدکننده خود عملکرد بهتری دارند. چارچوبی برای آموزش همزمان مدلهای عمیق تولیدکننده و تبعیضی میتواند از مزایای هر دو مدل بهرهمند شود، که انگیزهای برای شبکههای ترکیبی است.
مدلهای یادگیری عمیق ترکیبی به طور معمول از چندین مدل یادگیری عمیق پایه (دو مدل یا بیشتر) تشکیل شدهاند، جایی که مدل پایه یک مدل یادگیری عمیق تبعیضی یا تولیدکننده است که در بخشهای قبلی مورد بحث قرار گرفت. بر اساس ادغام مدلهای مختلف پایه تولیدکننده یا تبعیضی، سه دسته از مدلهای یادگیری عمیق ترکیبی در زیر ممکن است برای حل مسائل دنیای واقعی مفید باشند. این موارد به شرح زیر هستند:
ترکیبی 1
ادغام مدلهای مختلف تولیدکننده یا تبعیضی برای استخراج ویژگیهای معنادارتر و قویتر. مثالهایی از این نوع میتوان به CNN+LSTM، AE+GAN و غیره اشاره کرد.
ترکیبی 2
ادغام یک مدل تولیدکننده به دنبال یک مدل تبعیضی. مثالهایی از این نوع میتوان به DBN+MLP، GAN+CNN، AE+CNN و غیره اشاره کرد.
ترکیبی 3
ادغام یک مدل تولیدکننده یا تبعیضی به دنبال یک طبقهبندیکننده غیر یادگیری عمیق. مثالهایی از این نوع میتوان به AE+SVM، CNN+SVM و غیره اشاره کرد.
بنابراین، به طور کلی میتوان نتیجه گرفت که مدلهای ترکیبی بسته به هدف استفاده، میتوانند بر طبقهبندی تمرکز داشته باشند یا نداشته باشند. با این حال، اکثر مطالعات مرتبط با یادگیری ترکیبی در حوزه یادگیری عمیق بر طبقهبندی یا وظایف یادگیری تحت نظارت تمرکز دارند، که در جدول 1 خلاصه شده است. از مدلهای تولیدکننده بدون نظارت با بازنماییهای معنادار برای بهبود مدلهای تبعیضی استفاده میشود. مدلهای تولیدکننده با بازنمایی مفید میتوانند ویژگیهای آموزندهتر و کمبعدتری را برای تبعیض ارائه دهند و همچنین میتوانند با ارائه اطلاعات اضافی برای طبقهبندی، کیفیت و کمیت دادههای آموزشی را بهبود بخشند.
یادگیری انتقالی تکنیکی است که برای استفاده موثر از دانش مدلهای از پیش یادگرفتهشده برای حل یک کار جدید با حداقل آموزش یا تنظیم دقیق (fine-tuning) به کار میرود. دیپ لرنینگ (DL) در مقایسه با تکنیکهای یادگیری ماشین معمولی به حجم زیادی از داده آموزشی نیاز دارد. در نتیجه، نیاز به حجم قابل توجهی از دادههای برچسبدار مانعی اساسی برای رسیدگی به برخی از وظایف مهم حوزهی خاص، به ویژه در بخش پزشکی است، جایی که ایجاد مجموعه دادههای پزشکی یا بهداشتی با کیفیت بالا در مقیاس بزرگ هم دشوار و هم پرهزینه است. علاوه بر این، مدل DL استاندارد با وجود تلاشهای محققان برای بهبود آن، همچنان به منابع محاسباتی زیادی مانند سرور مجهز به GPU نیاز دارد. در نتیجه، دیپ لرنینگ انتقالی (DTL) که یک روش یادگیری انتقالی مبتنی بر DL است، ممکن است برای رفع این مشکل مفید باشد.
شکل 11 ساختار کلی فرآیند یادگیری انتقالی را نشان میدهد، جایی که دانش از مدل پیش-آموزش دیده به یک مدل DL جدید منتقل میشود. این روش به ویژه در حال حاضر در یادگیری عمیق بسیار محبوب است زیرا به آموزش شبکههای عصبی عمیق با داده بسیار کمی امکان میدهد [126].
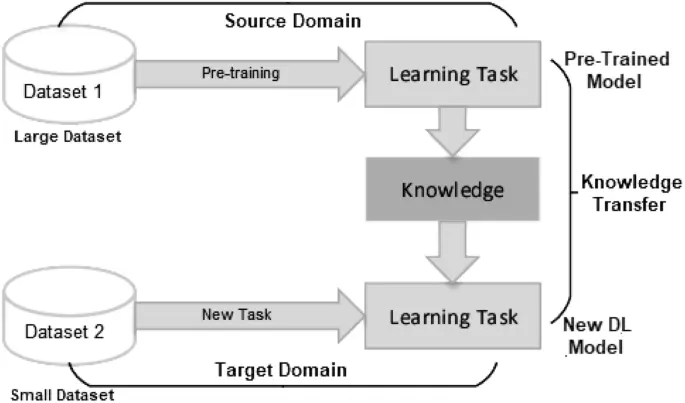
یادگیری انتقالی یک رویکرد دو مرحلهای برای آموزش یک مدل یادگیری عمیق است که از یک مرحله پیش-آموزش و یک مرحله تنظیم دقیق (fine-tuning) تشکیل شده است که در آن مدل برای وظیفه هدف آموزش داده میشود. از آنجایی که شبکههای عصبی عمیق در زمینههای مختلف محبوبیت پیدا کردهاند، تعداد زیادی از روشهای DTL ارائه شده است که دستهبندی و خلاصه کردن آنها را ضروری میکند. بر اساس تکنیکهای استفاده شده در منابع علمی، DTL را میتوان به چهار دسته تقسیم کرد . این موارد عبارتند از:
یادگیری انتقالی همچنین میتواند بسته به شرایط بین حوزه مبدا و حوزه هدف و فعالیتها، به یادگیری انتقالی القایی، استنتاجی و بدون نظارت طبقهبندی شود در حالی که اکثر تحقیقات فعلی بر یادگیری تحت نظارت متمرکز است، اینکه چگونه شبکههای عصبی عمیق میتوانند دانش را در یادگیری بدون نظارت یا نیمه-نظارت منتقل کنند، ممکن است در آینده مورد توجه بیشتری قرار گیرد.
از تکنیکهای DTL در زمینههای مختلفی از جمله پردازش زبان طبیعی، طبقهبندی احساسات، تشخیص بصری، تشخیص گفتار، فیلتر کردن اسپم و موارد مرتبط دیگر استفاده میشود.
یادگیری تقویتی رویکردی متفاوت از سایر رویکردهایی که تاکنون مورد بحث قرار دادهایم برای حل مسئله تصمیمگیری ترتیبی در پیش میگیرد. مفاهیم محیط (environment) و عامل (agent) اغلب اولین مفاهیمی هستند که در یادگیری تقویتی معرفی میشوند. عامل میتواند مجموعهای از اعمال را در محیط انجام دهد که هر کدام بر وضعیت محیط تأثیر میگذارد و میتواند منجر به پاداشهای احتمالی (بازخورد) شود – «مثبت» برای توالیهای خوب اعمال که منجر به حالت «خوب» میشود، و «منفی» برای توالیهای بد اعمال که منجر به حالت «بد» میشود. هدف از یادگیری تقویتی، یادگیری توالیهای عمل خوب از طریق تعامل با محیط است که معمولاً به عنوان یک خط مشی (policy) شناخته میشود.

یادگیری تقویتی عمیق (DRL یا deep RL) شبکههای عصبی را با معماری یادگیری تقویتی ادغام میکند تا به عوامل (agent) اجازه دهد اقدامات مناسب را در یک محیط مجازی بیاموزند، همانطور که در شکل ۱۲ نشان داده شدهاست. در حوزه یادگیری تقویتی، یادگیری تقویتی مبتنی بر مدل بر اساس یادگیری یک مدل گذار است که امکان مدلسازی محیط بدون تعامل مستقیم با آن را فراهم میکند، در حالی که روشهای یادگیری تقویتی بدون مدل مستقیماً از طریق تعامل با محیط یاد میگیرند.
Q-learning یک تکنیک محبوب یادگیری تقویتی بدون مدل برای تعیین بهترین خط مشی انتخاب عمل برای هر فرآیند تصمیمگیری مارکوف (MDP) (محدود) است. MDP یک چارچوب ریاضی برای مدلسازی تصمیمگیری بر اساس حالت، عمل و پاداش است. علاوه بر این، از شبکههای Q عمیق (Deep Q-Networks)، DQN دوبل (Double DQN)، یادگیری دوطرفه (Bi-directional Learning)، کنترل مونت کارلو (Monte Carlo Control) و غیره در این حوزه استفاده میشود.
در روشهای DRL، مدلهای یادگیری عمیق مانند شبکههای عصبی عمیق (DNN) بر اساس اصل MDP به عنوان تقریبزنندههای خط مشی و/یا تابع ارزش گنجانده میشوند. به عنوان مثال، CNN را میتوان به عنوان جزء عوامل RL برای یادگیری مستقیم از ورودیهای بصری خام و با ابعاد بالا استفاده کرد. در دنیای واقعی، راهحلهای مبتنی بر DRL را میتوان در چندین حوزه کاربردی از جمله رباتیک، بازیهای ویدئویی، پردازش زبان طبیعی، بینایی رایانه و موارد مرتبط دیگر به کار برد.

در طول سالهای گذشته، یادگیری عمیق با موفقیت در حل مشکلات متعدد در بسیاری از حوزههای کاربردی به کار گرفته شده است. این حوزهها شامل پردازش زبان طبیعی، تحلیل احساسات، امنیت سایبری، کسب و کار، دستیاران مجازی، تشخیص بصری، مراقبتهای بهداشتی، رباتیک و موارد بسیاری دیگر میشود. در شکل ۱۳، ما چندین حوزه کاربردی بالقوه یادگیری عمیق در دنیای واقعی را خلاصه کردهایم. همانطور که قبلاً گفته شد، تکنیکهای مختلف یادگیری عمیق مطابق با طبقهبندی ارائه شده در شکل ۶، که شامل یادگیری تبعیضی، یادگیری تولیدکننده و همچنین مدلهای ترکیبی است، در این حوزههای کاربردی به کار گرفته میشوند. در جدول ۱ نیز وظایف و تکنیکهای مختلف یادگیری عمیق را که برای حل وظایف مرتبط در چندین حوزه کاربردی دنیای واقعی استفاده میشوند، خلاصه کردهایم.
به طور کلی، از شکل ۱۳ و جدول ۱ میتوانیم نتیجه بگیریم که چشماندازهای آینده مدلسازی یادگیری عمیق در حوزههای کاربردی دنیای واقعی بسیار زیاد است و زمینههای کاری زیادی برای کار وجود دارد. در بخش بعدی، همچنین مسائل تحقیقاتی در مدلسازی یادگیری عمیق را خلاصه کرده و به جنبههای بالقوه برای مدلسازی نسل بعدی یادگیری عمیق اشاره میکنیم.
در حالی که روشهای موجود، پایه محکمی را برای سیستمهای یادگیری عمیق و تحقیقات در این زمینه ایجاد کردهاند، این بخش بر اساس مطالعه ما، ده مسیر تحقیقاتی بالقوه برای آینده را شرح میدهد.
۱. خودکارسازی در فرایند حاشیهنویسی داده
همانطور که در بخش ۳ با استناد به منابع موجود اشاره شد، اکثر مدلهای یادگیری عمیق از طریق مجموعه دادههای قابل دسترسی عمومی که حاشیهنویسی شدهاند، آموزش داده میشوند. با این حال، برای ساخت یک سیستم برای یک حوزه مسئله جدید یا یک سیستم مبتنی بر داده اخیر، به جمعآوری داده خام از منابع مرتبط نیاز است. بنابراین، حاشیهنویسی داده، به عنوان مثال دستهبندی، تگگذاری یا برچسبگذاری حجم زیادی از داده خام، برای ساخت مدلهای تبعیضی یادگیری عمیق یا وظایف تحت نظارت، که چالشبرانگیز است، مهم است.
روشی با قابلیت حاشیهنویسی داده به صورت خودکار و پویا، به جای حاشیهنویسی دستی یا استخدام حاشیهنویس، به ویژه برای مجموعه دادههای بزرگ، میتواند برای یادگیری تحت نظارت و همچنین به حداقل رساندن نیروی انسانی مؤثرتر باشد. بنابراین، بررسی عمیقتر روشهای جمعآوری و حاشیهنویسی داده، یا طراحی یک راهحل مبتنی بر یادگیری بدون نظارت میتواند یکی از مسیرهای اصلی تحقیق در حوزه مدلسازی یادگیری عمیق باشد.
۲. آمادهسازی داده برای تضمین کیفیت داده
همانطور که در سراسر این مقاله مورد بحث قرار گرفت، الگوریتمهای یادگیری عمیق تأثیر زیادی بر کیفیت داده و در دسترس بودن آن برای آموزش و در نتیجه بر مدل نهایی برای یک حوزه مسئله خاص دارند. بنابراین، مدلهای یادگیری عمیق ممکن است در صورت بد بودن داده، مانند کمبود داده، عدم نماینده بودن، کیفیت پایین، مقادیر مبهم، نویز، عدم تعادل داده، ویژگیهای نامرتبط، ناسازگاری داده، کمبود مقدار و غیره برای آموزش، بیارزش شوند یا دقت کمتری داشته باشند.
در نتیجه، چنین مشکلاتی در داده میتواند منجر به پردازش ضعیف و یافتههای نادرست شود که این یک مشکل اساسی در کشف بینش از داده است. بنابراین، مدلهای یادگیری عمیق نیز نیاز به انطباق با چنین مسائل رو به رشدی در داده دارند تا بتوانند اطلاعات تقریبی را از مشاهدات استخراج کنند. بنابراین، برای رسیدگی به چنین چالشهای نوظهوری، ممکن است به طراحی تکنیکهای موثر پیش پردازش داده متناسب با ماهیت مسئله داده و ویژگیهای آن نیاز باشد، که میتواند مسیر تحقیقاتی دیگری در این حوزه باشد.
۳. درک جعبه سیاه و انتخاب مناسب الگوریتم یادگیری عمیق/ماشین لرنینگ
به طور کلی، توضیح چگونگی به دست آمدن نتایج دیپ لرنینگ یا چگونگی اتخاذ تصمیمات نهایی توسط یک مدل خاص دشوار است. همانطور که در بخش ۲ مورد بحث قرار گرفت، اگرچه مدلهای یادگیری عمیق در حین یادگیری از مجموعه دادههای بزرگ به عملکرد قابل توجهی دست مییابند، این درک «جعبه سیاه» از مدلسازی یادگیری عمیق به طور معمول بیانگر تفسیر آماری ضعیف است که میتواند یک مشکل اساسی در این حوزه باشد.
از سوی دیگر، الگوریتمهای یادگیری ماشین، به ویژه تکنیکهای یادگیری ماشین مبتنی بر قانون، قوانین منطقی صریح (اگر-آنگاه) را برای تصمیمگیری ارائه میدهند که بر اساس برنامههای کاربردی هدف، تفسیر، بهروزرسانی یا حذف آنها آسانتر است. اگر الگوریتم یادگیری اشتباهی انتخاب شود، نتایج پیشبینی نشدهای ممکن است رخ دهد که منجر به اتلاف تلاش و همچنین کاهش اثربخشی و دقت مدل میشود. بنابراین، انتخاب مدل مناسب برای برنامه کاربردی هدف با در نظر گرفتن عملکرد، پیچیدگی، دقت مدل و قابلیت اعمال، چالشبرانگیز است و برای درک و تصمیمگیری بهتر نیاز به تحلیل عمیق است.
۴. شبکههای عمیق برای یادگیری تحت نظارت یا تبعیضی
با توجه به طبقهبندی طراحیشده ما از تکنیکهای یادگیری عمیق، همانطور که در شکل ۶ نشان داده شدهاست، معماریهای تبعیضی عمدتاً شامل MLP، CNN و RNN به همراه انواع آنها هستند که به طور گسترده در حوزههای کاربردی مختلف به کار میروند. با این حال، طراحی تکنیکهای جدید یا انواع آنها از چنین تکنیکهای تبعیضی با در نظر گرفتن بهینهسازی مدل، دقت و قابلیت اعمال، بر اساس برنامه کاربردی دنیای واقعی هدف و ماهیت داده، میتواند توسعه ای جدید باشد که میتواند به عنوان یک جنبه اصلی آینده در حوزه یادگیری تحت نظارت یا تبعیضی در نظر گرفته شود.
۵. شبکههای عمیق برای یادگیری بدون نظارت یا تولیدکننده
همانطور که در بخش ۳ مورد بحث قرار گرفت، یادگیری بدون نظارت یا مدلسازی یادگیری عمیق تولیدکننده، یکی از وظایف اصلی در این حوزه است، زیرا به ما امکان میدهد ویژگیها یا خصوصیات همبستگی مرتبه بالا (high-order correlation) را در دادهها توصیف کنیم، یا از طریق تحلیل اکتشافی، بازنمایی جدیدی از دادهها ایجاد کنیم. علاوه بر این، برخلاف یادگیری تحت نظارت ، به دلیل توانایی در استخراج بینش مستقیم از دادهها و همچنین تصمیمگیری مبتنی بر داده، نیازی به دادههای برچسبدار ندارد.
در نتیجه، از آن میتوان بهعنوان پیش پردازش برای یادگیری تحت نظارت یا مدلسازی تبعیضی و همچنین وظایف یادگیری نیمه-نظارت استفاده کرد که دقت یادگیری و کارایی مدل را تضمین میکند. با توجه به طبقهبندی طراحیشده ما از تکنیکهای یادگیری عمیق، همانطور که در شکل ۶ نشان داده شدهاست، تکنیکهای تولیدکننده عمدتاً شامل GAN، AE، SOM، RBM، DBN و انواع آنها هستند. بنابراین، طراحی تکنیکهای جدید یا انواع آنها برای مدلسازی یا بازنمایی موثر دادهها با توجه به برنامه کاربردی دنیای واقعی هدف میتواند یک (gòng xiàn) – contribution) جدید باشد که میتواند به عنوان یک جنبه اصلی آینده در حوزه یادگیری بدون نظارت یا تولیدکننده در نظر گرفته شود.
۶. مدلسازی ترکیبی (ansanburu – ensemble) و مدیریت عدم قطعیت
با توجه به طبقهبندی طراحیشده ما از تکنیکهای یادگیری عمیق، همانطور که در شکل ۶ نشان داده شدهاست، این مورد به عنوان یک دسته اصلی دیگر در وظایف یادگیری عمیق در نظر گرفته میشود. از آنجایی که مدلسازی ترکیبی از مزایای هر دو یادگیری تولیدکننده و تبعیضی بهره میبرد، یک ترکیب موثر میتواند از نظر عملکرد و همچنین مدیریت عدم قطعیت در برنامههای پرخطر، از سایر روشها پیشی بگیرد.
در بخش ۳، انواع مختلفی از ترکیبها را خلاصه کردهایم، به عنوان مثال AE+CNN/SVM. از آنجایی که گروهی از شبکههای عصبی با پارامترهای متمایز یا با مجموعههای آموزشی زیر نمونهگیری جداگانه آموزش داده میشوند، ترکیب یا آنسامبل چنین تکنیکهایی، یعنی یادگیری عمیق با یادگیری عمیق/ماشین لرنینگ، میتواند نقش کلیدی در این حوزه ایفا کند. بنابراین، طراحی ترکیبی موثر از مدلهای تبعیضی و تولیدکننده به جای روش ساده، میتواند یک فرصت تحقیقاتی مهم برای حل مسائل مختلف دنیای واقعی از جمله وظایف یادگیری نیمه-نظارت و عدم قطعیت مدل باشد.
۷. پویایی در انتخاب مقادیر آستانه/فوقمقدار و ساختارهای شبکه با کارایی محاسباتی
به طور کلی، رابطه بین عملکرد، پیچیدگی مدل و نیازهای محاسباتی، یک موضوع کلیدی در مدلسازی و کاربردهای یادگیری عمیق است. ترکیبی از پیشرفتهای الگوریتمی با دقت بهبود یافته و همچنین حفظ کارایی محاسباتی، یعنی دستیابی به حداکثر توان عملیاتی در عین حال مصرف کمترین منابع، بدون از دست دادن اطلاعات قابل توجه، میتواند منجر به جهشی در اثربخشی مدلسازی یادگیری عمیق در برنامههای کاربردی دنیای واقعی در آینده شود. مفهوم رویکردهای افزایشی یا یادگیری مبتنی بر تازگی [۱۰۰] ممکن است در چندین مورد بسته به ماهیت برنامههای کاربردی هدف مؤثر باشد.
علاوه بر این، فرض بر اینکه ساختارهای شبکه با تعداد ثابتی از گرهها و لایهها، مقادیر ابرپارامترها یا تنظیمات آستانه، یا انتخاب آنها با فرآیند آزمون و خطا باشد، در بسیاری از موارد مؤثر نخواهد بود، زیرا ممکن است به دلیل تغییرات داده تغییر کند. بنابراین، رویکرد مبتنی بر داده برای انتخاب پویای آنها در هنگام ساخت یک مدل یادگیری عمیق از نظر عملکرد و کاربردپذیری در دنیای واقعی میتواند مؤثرتر باشد. چنین نوعی از خودکارسازی مبتنی بر داده میتواند منجر به مدلسازی یادگیری عمیق نسل آینده با هوش اضافی شود که میتواند یک جنبه مهم آینده در این حوزه و همچنین یک مسیر تحقیقاتی مهم برای توسعه باشد.
۸. مدلسازی سبکوزن یادگیری عمیق برای دستگاههای هوشمند و برنامههای کاربردی نسل آینده
در سالهای اخیر، اینترنت اشیاء (IoT) که شامل میلیاردها چیز هوشمند و ارتباطی است و فناوریهای ارتباطات سیار برای تشخیص و جمعآوری اطلاعات انسانی و محیطی (به عنوان مثال، اطلاعات جغرافیایی، دادههای هواشناسی، دادههای زیستی، رفتارهای انسانی و غیره) برای انواع خدمات و برنامههای کاربردی هوشمند، محبوب شدهاست. این اشیاء هوشمند یا دستگاههای فراگیر هر روز حجم زیادی از داده را تولید میکنند که نیازمند پردازش سریع داده بر روی انواع دستگاههای هوشمند همراه است.
۹. گنجاندن دانش حوزه در مدلسازی یادگیری عمیق
دانش حوزه، در مقابل دانش عمومی یا دانش مستقل از حوزه، دانش یک موضوع یا زمینه خاص و تخصصی است. برای مثال، از نظر پردازش زبان طبیعی، ویژگیهای زبان انگلیسی معمولاً با زبانهای دیگر مانند بنگالی، عربی، فرانسوی و غیره متفاوت است. بنابراین، ادغام محدودیتهای مبتنی بر حوزه در مدل یادگیری عمیق میتواند نتایج بهتری را برای چنین هدف خاصی به همراه داشته باشد. برای نمونه، یک استخراجکننده ویژگی خاص وظیفه که دانش حوزه را در ساخت هوشمند برای تشخیص خطا در نظر میگیرد، میتواند مسائل موجود در روشهای سنتی مبتنی بر یادگیری عمیق را حل کند.
به طور مشابه، دانش حوزه در تحلیل تصویر پزشکی ، تحلیل احساسات مالی ، تحلیل امنیت سایبری و همچنین مدل داده مفهومی که در آن اطلاعات معنایی (یعنی معنادار برای یک سیستم، به جای صرفاً همبستگی) گنجانده شده است، میتواند نقشی حیاتی در این حوزه ایفا کند. یادگیری انتقال میتواند راهی مؤثر برای شروع یک چالش جدید با دانش حوزه باشد. علاوه بر این، اطلاعات زمینهای مانند زمینههای فضایی، زمانی، اجتماعی، محیطی نیز میتوانند برای گنجاندن محاسبات آگاه به زمینه با دانش حوزه برای تصمیمگیری هوشمند و همچنین ساخت سیستمهای تطبیقی و هوشمند آگاه به زمینه، نقش مهمی ایفا کنند. بنابراین، درک دانش حوزه و گنجاندن مؤثر آنها در مدل یادگیری عمیق میتواند مسیر تحقیقاتی دیگری باشد.
۱۰. طراحی چارچوب کلی یادگیری عمیق برای حوزههای کاربردی هدف
یکی از مسیرهای امیدوارکننده تحقیقاتی برای راهحلهای مبتنی بر دیپ لرنینگ، توسعه یک چارچوب کلی است که بتواند با تنوع دادهها، ابعاد، انواع تحریک و غیره مقابله کند. این چارچوب کلی به دو قابلیت کلیدی نیاز دارد: مکانیزم توجه که بر با ارزشترین بخشهای سیگنالهای ورودی تمرکز میکند، و توانایی درک ویژگی نهان (latent feature) که چارچوب را قادر میسازد تا ویژگیهای متمایز و آموزنده را جذب کند.
مدلهای توجه به دلیل شهودی بودن، تطبیقپذیری و قابلیت تفسیرشان، به یک موضوع تحقیقاتی محبوب تبدیل شدهاند و در حوزههای کاربردی مختلفی مانند بینایی رایانه، پردازش زبان طبیعی، طبقهبندی متن یا تصویر، تحلیل احساسات، سیستمهای توصیه، پروفایلسازی کاربر و غیره به کار گرفته میشوند. مکانیزم توجه را میتوان بر اساس الگوریتمهای یادگیری مانند یادگیری تقویتی که قادر به یافتن مفیدترین قسمت از طریق جستجوی سیاست است، اجرا کرد . به طور مشابه، CNN را میتوان با مکانیزمهای توجه مناسب برای ایجاد یک چارچوب طبقهبندی کلی ادغام کرد، جایی که CNN را میتوان به عنوان ابزاری برای یادگیری ویژگی برای دیگر ویژگیها در سطوح و دامنههای مختلف استفاده کرد.
بنابراین، طراحی یک چارچوب کلی یادگیری عمیق با در نظر گرفتن توجه و همچنین یک ویژگی نهان برای حوزههای کاربردی هدف میتواند مسیر دیگری برای توسعه باشد.
به طور خلاصه، دیپ لرنینگ موضوع نسبتاً بازی است که دانشگاهیان میتوانند با توسعه روشهای جدید یا بهبود روشهای موجود برای رسیدگی به نگرانیهای ذکر شده و حل مشکلات دنیای واقعی در حوزههای کاربردی مختلف به آن کمک کنند. این همچنین میتواند به محققان کمک کند تا تحلیل دقیقی از چالشهای پنهان و غیرمنتظره برنامه انجام دهند تا نتایج قابل اعتمادتر و واقعیتری حاصل شود. در مجموع، میتوانیم نتیجهگیری کنیم که رسیدگی به مسائل فوقالذکر و کمک به پیشنهاد تکنیکهای مؤثر و کارآمد میتواند منجر به مدلسازی «یادگیری عمیق نسل آینده» و همچنین کاربردهای هوشمندتر و خودکارتر شود.
در این مقاله، نمایهای ساختاریافته و جامع از فناوری یادگیری عمیق ارائه کردهایم که بهعنوان هستهای مرکزی از هوش مصنوعی و همچنین علم داده در نظر گرفته میشود. این مقاله با تاریخچه شبکههای عصبی مصنوعی شروع میشود و به تکنیکهای اخیر یادگیری عمیق و پیشرفتهای آنها در کاربردهای مختلف میپردازد. سپس، الگوریتمهای کلیدی در این حوزه، و همچنین مدلسازی شبکه عصبی عمیق در ابعاد مختلف مورد بررسی قرار میگیرد. برای این منظور، ما همچنین طبقهبندیای را با در نظر گرفتن تغییرات وظایف یادگیری عمیق و نحوه استفاده از آنها برای اهداف مختلف ارائه کردهایم. در مطالعه جامع خود، نه تنها شبکههای عمیق برای یادگیری تحت نظارت یا تبعیضی را در نظر گرفتهایم، بلکه شبکههای عمیق برای یادگیری بدون نظارت یا تولیدکننده و یادگیری ترکیبی را نیز در نظر گرفتهایم که میتوان از آنها برای حل مسائل مختلف دنیای واقعی بر اساس ماهیت مشکلات استفاده کرد.
یادگیری عمیق، برخلاف الگوریتمهای سنتی یادگیری ماشین و استخراج داده، میتواند بازنماییهای سطح بسیار بالایی از دادهها را از حجم عظیمی از دادههای خام تولید کند. در نتیجه، راهحلی عالی برای انواع مشکلات دنیای واقعی ارائه کرده است. یک تکنیک موفق یادگیری عمیق باید بسته به ویژگیهای دادههای خام، مدلسازی مبتنی بر داده مرتبط را داشته باشد. سپس الگوریتمهای یادگیری پیچیده باید قبل از اینکه سیستم بتواند به تصمیمگیری هوشمندانه کمک کند، از طریق دادههای جمعآوریشده و دانش مرتبط با برنامه کاربردی هدف، آموزش داده شوند. یادگیری عمیق نشان داده است که در طیف گستردهای از کاربردها و زمینههای تحقیقاتی مانند مراقبتهای بهداشتی، تحلیل احساسات، تشخیص بصری، هوش تجاری، امنیت سایبری و بسیاری دیگر که در مقاله خلاصه شدهاند، مفید است.
در نهایت، چالشها و مسیرهای بالقوه تحقیقاتی و جنبههای آینده در این حوزه را خلاصه و مورد بحث قرار دادهایم. اگرچه یادگیری عمیق به دلیل استدلال ضعیف و تفسیرپذیری پایین، برای بسیاری از برنامهها راهحلی جعبه سیاه در نظر گرفته میشود، اما پرداختن به چالشها یا جنبههای آیندهای که شناسایی شدهاند، میتواند به مدلسازی یادگیری عمیق نسل آینده و سیستمهای هوشمندتر منجر شود. این همچنین میتواند به محققان برای تحلیل عمیقتر برای دستیابی به نتایج قابل اعتمادتر و واقعیتر کمک کند. در مجموع، بر این باوریم که مطالعه ما در مورد شبکههای عصبی و تحلیلهای پیشرفته مبتنی بر یادگیری عمیق، مسیر امیدوارکنندهای را نشان میدهد و میتواند بهعنوان راهنمای مرجع برای تحقیقات و پیادهسازیهای آتی در حوزههای کاربردی مرتبط توسط متخصصان دانشگاهی و صنعتی مورد استفاده قرار گیرد.
منبع:


ربات های همکار، انقلابی در اتوماسیون چشمانداز صنعتی شاهد تحولی چشمگیر است که توسط افزایش پیچیدگی و پذیرش رباتهای همکار هدایت میشود. این ماشینهای ماهر، که برای کار در کنار انسانها طراحی شدهاند، فراتر از اتوماسیون به همتیمیهای هوشمندی تبدیل میشوند که بر ایمنی، بهرهوری و پایداری تأثیر میگذارند. ارتقاء ایمنی ایمنی اهمیت فوقالعادهای دارد. […]

در عصر دیجیتال زندگی می کنیم و فناوری، زندگی ما را کاملاً متحول کرده و تقریباً در تمام جنبه ها وجود دارد. در طول سال های اخیر، فناوری رباتیک آموزشی به عنوان یکی از مسیرهای اصلی، راه خود را به بخش آموزش نیز باز کرده است. رباتها که زمانی فقط شخصیتهای علمی-تخیلی بودند، جای خود […]

ربات آشپز دوبات در توکیو از نوزدهم تا بیست و دوم فوریه، نمایشگاه HCJ2019 در توکیو برگزار شد، جایی که شرکت ژاپنی Connected Robotics ربات جادویی Dobot را به یک ربات آشپزی تبدیل کرد که می تواند هم صبحانه درست کند و هم بستنی سرو کند. این ربات توجه زیادی را از سوی تماشاگران و […]

-1-1024x576-1.jpg)
دیدگاهتان را بنویسید